Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Screaming From occurences and canonicals what does it all mean
-
Bonjourno from Wetherby UK...
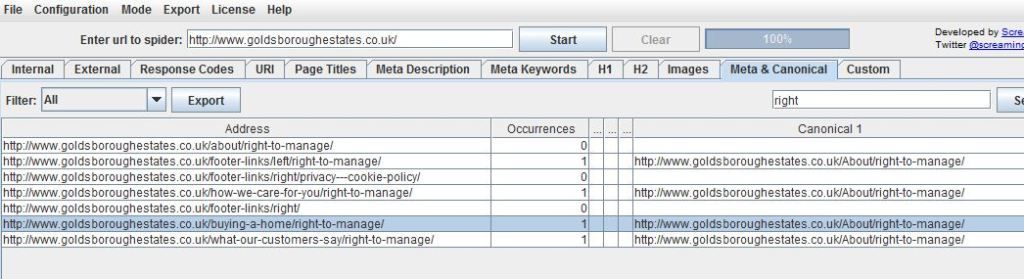
Ive used a package called screamong frog to diagnose canonical errors but can anyone tell me what this means? http://i216.photobucket.com/albums/cc53/zymurgy_bucket/understand-occurances-canonical.jpg
Thanks in advance.
David
-
Thank you for all your replies this was bugging me but the pain of not knowing has vanished like the morning mist as the warming glow of sunshine illumunates truth
")
-
David
Looks like you may have an issue there. The "address" and "canonical 1" should match about 99% of the time. Right now you're telling Google to index all those different address pages as a single URL (About/right-to-manage)... something to look at - and the suggestions below are both good as well.
-Dan
-
I agree with what Streamline Metrics said, I just want to add to this by linking you to a great SEOmoz post on canonicalization which may help you clear things up more.
In your case, having 1 rel="canonical" tag per page is what you want, so you should be fine with that, just make sure that the canonical tags (listed under canonical 1 in Screaming Frog) is the actual URL that you want.
Hope this helps
Zach -
It simply means how many canonical tags are found on that specific page. So if you had two rel=canonical tags on a page, it would say 2 occurrences. For more info, check out http://www.screamingfrog.co.uk/seo-spider/user-guide/tabs/
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Dynamic Canonical Tag for Search Results Filtering Page
Hi everyone, I run a website in the travel industry where most users land on a location page (e.g. domain.com/product/location, before performing a search by selecting dates and times. This then takes them to a pre filtered dynamic search results page with options for their selected location on a separate URL (e.g. /book/results). The /book/results page can only be accessed on our website by performing a search, and URL's with search parameters from this page have never been indexed in the past. We work with some large partners who use our booking engine who have recently started linking to these pre filtered search results pages. This is not being done on a large scale and at present we only have a couple of hundred of these search results pages indexed. I could easily add a noindex or self-referencing canonical tag to the /book/results page to remove them, however it’s been suggested that adding a dynamic canonical tag to our pre filtered results pages pointing to the location page (based on the location information in the query string) could be beneficial for the SEO of our location pages. This makes sense as the partner websites that link to our /book/results page are very high authority and any way that this could be passed to our location pages (which are our most important in terms of rankings) sounds good, however I have a couple of concerns. • Is using a dynamic canonical tag in this way considered spammy / manipulative? • Whilst all the content that appears on the pre filtered /book/results page is present on the static location page where the search initiates and which the canonical tag would point to, it is presented differently and there is a lot more content on the static location page that isn’t present on the /book/results page. Is this likely to see the canonical tag being ignored / link equity not being passed as hoped, and are there greater risks to this that I should be worried about? I can’t find many examples of other sites where this has been implemented but the closest would probably be booking.com. https://www.booking.com/searchresults.it.html?label=gen173nr-1FCAEoggI46AdIM1gEaFCIAQGYARS4ARfIAQzYAQHoAQH4AQuIAgGoAgO4ArajrpcGwAIB0gIkYmUxYjNlZWMtYWQzMi00NWJmLTk5NTItNzY1MzljZTVhOTk02AIG4AIB&sid=d4030ebf4f04bb7ddcb2b04d1bade521&dest_id=-2601889&dest_type=city& Canonical points to https://www.booking.com/city/gb/london.it.html In our scenario however there is a greater difference between the content on both pages (and booking.com have a load of search results pages indexed which is not what we’re looking for) Would be great to get any feedback on this before I rule it out. Thanks!
Technical SEO | | GAnalytics1 -

Does using a canonical with ?utm_source=gmb cause any issues?
All of our URLs in Google My Business are tagged with ?utm_source=gmb. This way when people click on it within a Google Map listing, knowledge graph, etc we know it came from there. I'm assuming using a canonical on all ?_utm_source _pages (we have others, including some in the index) won't cause any problems with this, correct? Since they're not technically traditional organic SERPs? Dumb question I know, but better safe than sorry. Thanks.
Technical SEO | | Alces1 -

Broken canonical link errors
Hello, Several tools I'm using are returning errors due to "broken canonical links". However, I'm not too sure why is that. Eg.
Technical SEO | | GhillC
Page URL: domain.com/page.html?xxxx
Canonical link URL: domain.com/page.html
Returns an error. Any idea why? Am I doing it wrong? Thanks,
G1 -

Does Google read dynamic canonical tags?
Does Google recognize rel=canonical tag if loaded dynamically via javascript? Here's what we're using to load: <script> //Inject canonical link into page head if (window.location.href.indexOf("/subdirname1") != -1) { canonicalLink = window.location.href.replace("/kapiolani", ""); } if (window.location.href.indexOf("/subdirname2") != -1) { canonicalLink = window.location.href.replace("/straub", ""); } if (window.location.href.indexOf("/subdirname3") != -1) { canonicalLink = window.location.href.replace("/pali-momi", ""); } if (window.location.href.indexOf("/subdirname4") != -1) { canonicalLink = window.location.href.replace("/wilcox", ""); } if (canonicalLink != window.location.href) { var link = document.createElement('link'); link.rel = 'canonical'; link.href = canonicalLink; document.head.appendChild(link); } script>
Technical SEO | | SoulSurfer80 -

Can you use Screaming Frog to find all instances of relative or absolute linking?
My client wants to pull every instance of an absolute URL on their site so that they can update them for an upcoming migration to HTTPS (the majority of the site uses relative linking). Is there a way to use the extraction tool in Screaming Frog to crawl one page at a time and extract every occurrence of _href="http://" _? I have gone back and forth between using an x-path extractor as well as a regex and have had no luck with either. Ex. X-path: //*[starts-with(@href, “http://”)][1] Ex. Regex: href=\”//
Technical SEO | | Merkle-Impaqt0 -

Rel canonical between mirrored domains
Hi all & happy new near! I'm new to SEO and could do with a spot of advice: I have a site that has several domains that mirror it (not good, I know...) So www.site.com, www.site.edu.sg, www.othersite.com all serve up the same content. I was planning to use rel="canonical" to avoid the duplication but I have a concern: Currently several of these mirrors rank - one, the .com ranks #1 on local google search for some useful keywords. the .edu.sg also shows up as #9 for a dirrerent page. In some cases I have multiple mirrors showing up on a specific serp. I would LIKE to rel canonical everything to the local edu.sg domain since this is most representative of the fact that the site is for a school in Singapore but...
Technical SEO | | AlexSG
-The .com is listed in DMOZ (this used to be important) and none of the volunteers there ever respoded to requests to update it to the .edu.sg
-The .com ranks higher than the com.sg page for non-local search so I am guessing google has some kind of algorithm to mark down obviosly local domains in other geographic locations Any opinions on this? Should I rel canonical the .com to the .edu.sg or vice versa? I appreciate any advice or opinion before I pull the trigger and end up shooting myself in the foot! Best regards from Singapore!0 -

Duplicate title-tags with pagination and canonical
Some time back we implemented the Google recommendation for pagination (the rel="next/prev"). GWMT now reports 17K pages with duplicate title-tags (we have about 1,1m products on our site and about 50m pages indexed in Google) As an example we have properties listed in various states and the category title would be "Properties for Sale in [state-name]". A paginated search page or browsing a category (see also http://searchengineland.com/implementing-pagination-attributes-correctly-for-google-114970) would then include the following: The title for each page is the same - so to avoid the duplicate title-tags issue, I would think one would have the following options: Ignore what Google says Change the canonical to http://www.site.com/property/state.html (which would then only show the first XX results) Append a page number to the title "Properties for Sale in [state-name] | Page XX" Have all paginated pages use noindex,follow - this would then result in no category page being indexed Would you have the canonical point to the individual paginated page or the base page?
Technical SEO | | MagicDude4Eva2 -

Internal search : rel=canonical vs noindex vs robots.txt
Hi everyone, I have a website with a lot of internal search results pages indexed. I'm not asking if they should be indexed or not, I know they should not according to Google's guidelines. And they make a bunch of duplicated pages so I want to solve this problem. The thing is, if I noindex them, the site is gonna lose a non-negligible chunk of traffic : nearly 13% according to google analytics !!! I thought of blocking them in robots.txt. This solution would not keep them out of the index. But the pages appearing in GG SERPS would then look empty (no title, no description), thus their CTR would plummet and I would lose a bit of traffic too... The last idea I had was to use a rel=canonical tag pointing to the original search page (that is empty, without results), but it would probably have the same effect as noindexing them, wouldn't it ? (never tried so I'm not sure of this) Of course I did some research on the subject, but each of my finding recommanded one of the 3 methods only ! One even recommanded noindex+robots.txt block which is stupid because the noindex would then be useless... Is there somebody who can tell me which option is the best to keep this traffic ? Thanks a million
Technical SEO | | JohannCR0