Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Blocking certain countries via IP address location
-
We are a US based company that ships only to US and Canada. We've had two issues arise recently from foreign countries (Russia namely) that caused us to block access to our site from anyone attempting to interact with our store from outside of the US and Canada.
1. The first issue we encountered were fraudulent orders originating from Russia (using stolen card data) and then shipping to a US based International shipping aggregator.
2. The second issue was a consistent flow of Russian based "new customer" entries.
My question to the MOZ community is this: are their any unintended consequences, from an SEO perspective, to blocking the viewing of our store from certain countries.
-
Both answers above are correct and great ones.
From a strategical point of view, formally blocking russian IPs does not have any SEO effect in your case, because - as a business - you don't even need an SEO strategy for the Russian market.
-
Fully agree with Peter, very easy to bypass IP blocking these days, there are some sophisticated systems that can still detect but mostly outside the range of us mere mortals!
If you block a particular country from crawling your website it is pretty certain you will not rank in that country (which I guess isn't a problem anyway) but I suspect this would only have a very limited (if any) impact on your rankings in other countries.
We have had a similar issue, here are a couple of ideas.
1. When someone places an order use a secondary method of validation.
2. With the new customer entries/registrations make sure you have a good captcha, most of this sort of thing tends to be from bots. A captcha Will often fix that problem.
-
Blocking IPs on geolocation can be dangerous. But you can use MaxMind GeoIP database:
https://github.com/maxmind/geoip-api-php
or you also can implemente GeoIP in "add to cart" or "new user" as additional check. So when user is outside of US/CA you can require them to fill captcha or just ignore their requests.Now from bot point of view - if bot visit with US IP and with UK (example) IP they will see same pages. Just within UK they can't create new user or adding to cart. HTML code will be 100% same.
PS: I forgot... VPN or Proxies are cheap these days. I have few EC2 instances with everything just for mine own needs. Bad Guys also can use them so think twice about possible "protection". Note the quotes.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Best way to link to multiple location pages
I am a Magician and have multiple location pages for each county I cover. I currently have them linked off the menu under locations/ <county>and also in the footer</county> However I have heard that a link from the page is much stronger, so I am experimenting with removing the Menu & Footer link and just linking to these pages from within the content. It's not really a navigation item and most people come in through search to the right page. Am I diluting the link by having it in the Menu/Page and Footer? I read a long time ago that Google only considers the first link to a page and ignores the rest - is that the case? Thanks Roger https://www.rogerlapin.co.uk/
Technical SEO | | Rogerperk0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
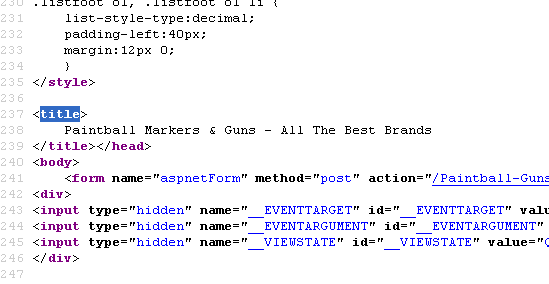 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

International architecture: Country specific subfolders > domain mapping to tld
Hi Ive got a clients dev saying they are setting up with country/language specific subfolders (as i recommended) BUT now they are saying they want to set up on network.domain.com (for example) and then each language will have its own sub-folder BUT will be domain mapped to the TLD as and when they get them. I have asked them to clarify since sounds a bit strange since thought best to have domain.com then /uk and /us etc etc and sure ok to forward country specific TLD's to these subfolders. Its this new subdomain (network.) thats concerning me and mapping rather than forwarding (or is it the same thing) but anyone know off hand if above sounds ok or also thinks a bit strange or know issues with such a set up ? many thanks dan
Technical SEO | | Dan-Lawrence0 -

Blocked URL parameters can still be crawled and indexed by google?
Hy guys, I have two questions and one might be a dumb question but there it goes. I just want to be sure that I understand: IF I tell webmaster tools to ignore an URL Parameter, will google still index and rank my url? IS it ok if I don't append in the url structure the brand filter?, will I still rank for that brand? Thanks, PS: ok 3 questions :)...
Technical SEO | | catalinmoraru0 -

Blocking Affiliate Links via robots.txt
Hi, I work with a client who has a large affiliate network pointing to their domain which is a large part of their inbound marketing strategy. All of these links point to a subdomain of affiliates.example.com, which then redirects the links through a 301 redirect to the relevant target page for the link. These links have been showing up in Webmaster Tools as top linking domains and also in the latest downloaded links reports. To follow guidelines and ensure that these links aren't counted by Google for either positive or negative impact on the site, we have added a block on the robots.txt of the affiliates.example.com subdomain, blocking search engines from crawling the full subddomain. The robots.txt file is the following code: User-agent: * Disallow: / We have authenticated the subdomain with Google Webmaster Tools and made certain that Google can reach and read the robots.txt file. We know they are being blocked from reading the affiliates subdomain. However, we added this affiliates subdomain block a few weeks ago to the robots.txt, but links are still showing up in the latest downloads report as first being discovered after we added the block. It's been a few weeks already, and we want to make sure that the block was implemented properly and that these links aren't being used to negatively impact the site. Any suggestions or clarification would be helpful - if the subdomain is being blocked for the search engines, why are the search engines following the links and reporting them in the www.example.com subdomain GWMT account as latest links. And if the block is implemented properly, will the total number of links pointing to our site as reported in the links to your site section be reduced, or does this not have an impact on that figure?From a development standpoint, it's a much easier fix for us to adjust the robots.txt file than to change the affiliate linking connection from a 301 to a 302, which is why we decided to go with this option.Any help you can offer will be greatly appreciated.Thanks,Mark
Technical SEO | | Mark_Ginsberg0 -

How Does Google's "index" find the location of pages in the "page directory" to return?
This is my understanding of how Google's search works, and I am unsure about one thing in specific: Google continuously crawls websites and stores each page it finds (let's call it "page directory") Google's "page directory" is a cache so it isn't the "live" version of the page Google has separate storage called "the index" which contains all the keywords searched. These keywords in "the index" point to the pages in the "page directory" that contain the same keywords. When someone searches a keyword, that keyword is accessed in the "index" and returns all relevant pages in the "page directory" These returned pages are given ranks based on the algorithm The one part I'm unsure of is how Google's "index" knows the location of relevant pages in the "page directory". The keyword entries in the "index" point to the "page directory" somehow. I'm thinking each page has a url in the "page directory", and the entries in the "index" contain these urls. Since Google's "page directory" is a cache, would the urls be the same as the live website (and would the keywords in the "index" point to these urls)? For example if webpage is found at wwww.website.com/page1, would the "page directory" store this page under that url in Google's cache? The reason I want to discuss this is to know the effects of changing a pages url by understanding how the search process works better.
Technical SEO | | reidsteven750 -

Temporarily suspend Googlebot without blocking users
We'll soon be launching a redesign, on a new platform, migrating millions of pages to new URLs. How can I tell Google (and other crawlers) to temporarily (a day or two) ignore my site? We're hoping to buy ourselves a small bit of time to verify redirects and live functionality before allowing Google to crawl and index the new architecture. GWT's recommendation is to 503 all pages - including robots.txt, but that also makes the site invisible to real site visitors, resulting in significant business loss. Bad answer. I've heard some recommendations to disallow all user agents in robots.txt. Any answer that puts the millions of pages we already have indexed at risk is also a bad answer. Thanks
Technical SEO | | lzhao0 -

Multiple Domains on 1 IP Address
We have multiple domains on the same C Block IP Address. Our main site is an eCommerce site, and we have separate domains for each of the following: our company blog (and other niche blogs), forum site, articles site and corporate site. They are all on the same server and hosted by the same web-hosting company. They all have unique and different content. Speaking strictly from a technical standpoint, could this be hurting us? Can you please make a recommendation for the best practices when it comes to multiple domains like these and having separate or the same IP Addresses? Thank you!
Technical SEO | | Motivators0