Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
A question about RSS feeds and nofollow's
-
With the nofollow tag used very widely on the internet these days I was just wondering about how an RSS feed might help me find a way around it. Basically my question is this : I post a comment on a blog, it's approved and my comment together with my link(nofollow tag applied) is there. Now when the blogs RSS feed updates, does this nofollow tag get applied to the feed? As far as I can tell it does not - but I'm not too clue'd up on how the feed is generated.
Anyone want to help me understand how it works and if what I'm suggesting would be 'a way around the nofollow tag' ?
Thanks
")
-
Thanks Alan - I'm not looking for brute force link building was just curious about the concept
-
@Alan +1
-
Regardless of whether they're updated or not, RSS feeds are generating duplicate content and not the original source, so the value is going to be either none, or more likely, less than comments on an original source. And if you're actually here asking this question, I'd suggest that unless you perform a specific test, in a specific situation across a specific market niche, you're not always going to get the same results.
And unless you're looking for brute force link building, it seems like a poor time expense to pursue these given the dupe-content factor. And if you are looking for brute force link building, don't rely on this method being sustainable.
-
What about dynamically created blogs and databases - surely comments are also stored in the database and then retrieved when the visitor requests the 'page' ? That would keep updating the feed atleast daily when the cron job is run?
And the commentRSS feed is a dofollow? That can be indexed by the search engine and still sits on the domain? Cos that then sounds to me like a dofollow link coming effectively from the domain of the blog?!
-
If you are talking about a commentRSS feed yes, it´s updated when you write a new comment, but the RSS show nofollow tag too. If you are talking about a normal blog RSSfeed, the new comments don´t update the RSS.
-
Surely that can'y be the case - since one of the uses for an RSS feed is to track when someone has replied to your comment/made another comment?
-
Yes, and the comments don´t update the blog RSS feed.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Google has deindexed a page it thinks is set to 'noindex', but is in fact still set to 'index'
A page on our WordPress powered website has had an error message thrown up in GSC to say it is included in the sitemap but set to 'noindex'. The page has also been removed from Google's search results. Page is https://www.onlinemortgageadvisor.co.uk/bad-credit-mortgages/how-to-get-a-mortgage-with-bad-credit/ Looking at the page code, plus using Screaming Frog and Ahrefs crawlers, the page is very clearly still set to 'index'. The SEO plugin we use has not been changed to 'noindex' the page. I have asked for it to be reindexed via GSC but I'm concerned why Google thinks this page was asked to be noindexed. Can anyone help with this one? Has anyone seen this before, been hit with this recently, got any advice...?
Technical SEO | | d.bird0 -

What's the best way for users to upload their images to my wordpress site to promote UGC
I have looked at lots of different plugins and wanted a recommendation for an easy way for patients of ours to upload pictures of them out partying and having fun and looking beautiful so future users can see the final results instead of sometimes gory or difficult to understand before and after images. I'd like to give them the opportunity to write captions (like facebook or insta posts and would offer them incentives to do so. I don't want it to be too complicated for them or have too many steps or barriers but I do want it to look nice and slick and modern. Also do you think this would have a positive impact on SEO? I was also thinking of a Q&A app where dentists could get Q&A emails and respond - i've been doing AMA sessions and they've been really successful and I would like to bring it into out site and make it native. Thanks in advance 🙂
Technical SEO | | Smileworks_Liverpool1 -

Soft 404's on a 301 Redirect...Why?
So we launched a site about a month ago. Our old site had an extensive library of health content that went away with the relaunch. We redirected this entire section of the site to the new education materials, but we've yet to see this reflected in the index or in GWT. In fact, we're getting close to 500 soft 404's in GWT. Our development team confirmed for me that the 301 redirect is configured correctly. Is it just a waiting game at this point or is there something I might be missing? Any help is appreciated. Thanks!
Technical SEO | | MJTrevens0 -

Good alternatives to Xenu's Link Sleuth and AuditMyPc.com Sitemap Generator
I am working on scraping title tags from websites with 1-5 million pages. Xenu's Link Sleuth seems to be the best option for this, at this point. Sitemap Generator from AuditMyPc.com seems to be working too, but it starts handing up, when a sitemap file, the tools is working on,becomes too large. So basically, the second one looks like it wont be good for websites of this size. I know that Scrapebox can scrape title tags from list of url, but this is not needed, since this comes with both of the above mentioned tools. I know about DeepCrawl.com also, but this one is paid, and it would be very expensive with this amount of pages and websites too (5 million ulrs is $1750 per month, I could get a better deal on multiple websites, but this obvioulsy does not make sense to me, it needs to be free, more or less). Seo Spider from Screaming Frog is not good for large websites. So, in general, what is the best way to work on something like this, also time efficient. Are there any other options for this? Thanks.
Technical SEO | | blrs120 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
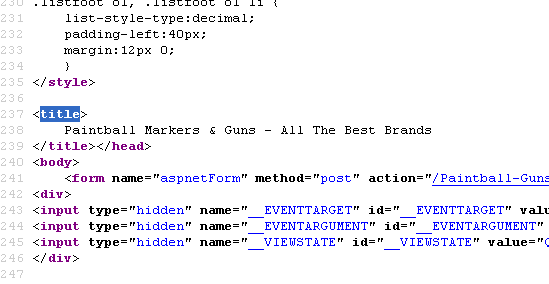 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Http to https - is a '302 object moved' redirect losing me link juice?
Hi guys, I'm looking at a new site that's completely under https - when I look at the http variant it redirects to the https site with "302 object moved" within the code. I got this by loading the http and https variants into webmaster tools as separate sites, and then doing a 'fetch as google' across both. There is some traffic coming through the http option, and as people start linking to the new site I'm worried they'll link to the http variant, and the 302 redirect to the https site losing me ranking juice from that link. Is this a correct scenario, and if so, should I prioritise moving the 302 to a 301? Cheers, Jez
Technical SEO | | jez0000 -

Correct linking to the /index of a site and subfolders: what's the best practice? link to: domain.com/ or domain.com/index.html ?
Dear all, starting with my .htaccess file: RewriteEngine On
Technical SEO | | inlinear
RewriteCond %{HTTP_HOST} ^www.inlinear.com$ [NC]
RewriteRule ^(.*)$ http://inlinear.com/$1 [R=301,L] RewriteCond %{THE_REQUEST} ^./index.html
RewriteRule ^(.)index.html$ http://inlinear.com/ [R=301,L] 1. I redirect all URL-requests with www. to the non www-version...
2. all requests with "index.html" will be redirected to "domain.com/" My questions are: A) When linking from a page to my frontpage (home) the best practice is?: "http://domain.com/" the best and NOT: "http://domain.com/index.php" B) When linking to the index of a subfolder "http://domain.com/products/index.php" I should link also to: "http://domain.com/products/" and not put also the index.php..., right? C) When I define the canonical ULR, should I also define it just: "http://domain.com/products/" or in this case I should link to the definite file: "http://domain.com/products**/index.php**" Is A) B) the best practice? and C) ? Thanks for all replies! 🙂
Holger0 -

How Does Google's "index" find the location of pages in the "page directory" to return?
This is my understanding of how Google's search works, and I am unsure about one thing in specific: Google continuously crawls websites and stores each page it finds (let's call it "page directory") Google's "page directory" is a cache so it isn't the "live" version of the page Google has separate storage called "the index" which contains all the keywords searched. These keywords in "the index" point to the pages in the "page directory" that contain the same keywords. When someone searches a keyword, that keyword is accessed in the "index" and returns all relevant pages in the "page directory" These returned pages are given ranks based on the algorithm The one part I'm unsure of is how Google's "index" knows the location of relevant pages in the "page directory". The keyword entries in the "index" point to the "page directory" somehow. I'm thinking each page has a url in the "page directory", and the entries in the "index" contain these urls. Since Google's "page directory" is a cache, would the urls be the same as the live website (and would the keywords in the "index" point to these urls)? For example if webpage is found at wwww.website.com/page1, would the "page directory" store this page under that url in Google's cache? The reason I want to discuss this is to know the effects of changing a pages url by understanding how the search process works better.
Technical SEO | | reidsteven750