Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Are Collapsible DIV's SEO-Friendly?
-
When I have a long article about a single topic with sub-topics I can make it user friendlier when I limit the text and hide text just showing the next headlines, by using expandable-collapsible div's.
My doubt is if Google is really able to read onclick textlinks (with javaScript) or if it could be "seen" as hidden text?
I think I read in the SEOmoz Users Guide, that all javaScript "manipulated" contend will not be crawled. So from SEOmoz's Point of View I should better make use of old school named anchors and a side-navigation to jump to the sub-topics?
(I had a similar question in my post before, but I did not use the perfect terms to describe what I really wanted. Also my text is not too long (<1000 Words) that I should use pagination with rel="next" and rel="prev" attributes.)
THANKS for every answer
")
-
Expandable and collapible DIV's are just fine for SEO. They do a great job of accomplishing great design without compromsing content for SEO. Yes, Google can crawl that content just fine. Here's a link to a great webinar that specifically addresses some great Pro-Tips regarding how best to use these: http://www.seomoz.org/webinars/designing-for-seo
Hope that helps!
Dana
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Google has deindexed a page it thinks is set to 'noindex', but is in fact still set to 'index'
A page on our WordPress powered website has had an error message thrown up in GSC to say it is included in the sitemap but set to 'noindex'. The page has also been removed from Google's search results. Page is https://www.onlinemortgageadvisor.co.uk/bad-credit-mortgages/how-to-get-a-mortgage-with-bad-credit/ Looking at the page code, plus using Screaming Frog and Ahrefs crawlers, the page is very clearly still set to 'index'. The SEO plugin we use has not been changed to 'noindex' the page. I have asked for it to be reindexed via GSC but I'm concerned why Google thinks this page was asked to be noindexed. Can anyone help with this one? Has anyone seen this before, been hit with this recently, got any advice...?
Technical SEO | | d.bird0 -

Can I use a 301 redirect to pass 'back link' juice to a different domain?
Hi, I have a backlink from a high DA/PA Government Website pointing to www.domainA.com which I own and can setup 301 redirects on if necessary. However my www.domainA.com is not used and has no active website (but has hosting available which can 301 redirect). www.domainA.com is also contextually irrelevant to the backlink. I want the Government Website link to go to www.domainB.com - which is both the relevant site and which also should be benefiting from from the seo juice from the backlink. So far I have had no luck to get the Government Website's administrators to change the URL on the link to point to www.domainB.com. Q1: If i use a 301 redirect on www.domainA.com to redirect to www.domainB.com will most of the backlink's SEO juice still be passed on to www.domainB.com? Q2: If the answer to the above is yes - would there be benefit to taking this a step further and redirect www.domainA.com to a deeper directory on www.domianB.com which is even more relevant?
Technical SEO | | DGAU
ie. redirect www.domainA.com to www.domainB.com/categoryB - passing the link juice deeper.0 -

Spam URL'S in search results
We built a new website for a client. When I do 'site:clientswebsite.com' in Google it shows some of the real, recently submitted pages. But it also shows many pages of spam url results, like this 'clientswebsite.com/gockumamaso/22753.htm' - all of which then go to the sites 404 page. They have page titles and meta descriptions in Chinese or Japanese too. Some of the urls are of real pages, and link to the correct page, despite having the same Chinese page titles and descriptions in the SERPS. When I went to remove all the spammy urls in Search Console (it only allowed me to temporarily hide them), a whole load of new ones popped up in the SERPS after a day or two. The site files itself are all fine, with no errors in the server logs. All the usual stuff...robots.txt, sitemap etc seems ok and the proper pages have all been requested for indexing and are slowly appearing. The spammy ones continue though. What is going on and how can I fix it?
Technical SEO | | Digital-Murph0 -

New theme adds ?v=1d20b5ff1ee9 to all URL's as part of cache. How does this affect SEO
New theme I am working in ads ?v=1d20b5ff1ee9 to every URL. Theme developer says its a server setting issue. GoDaddy support says its part of cache an becoming prevalent in new themes. How does this impact SEO?
Technical SEO | | DML-Tampa0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
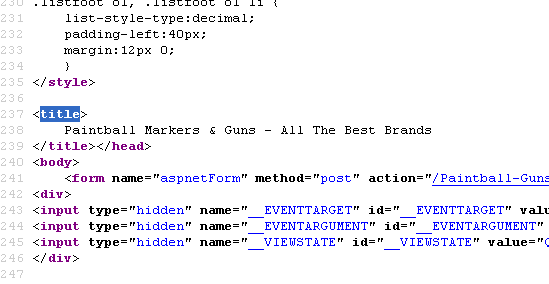 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Is there a way for me to automatically download a website's sitemap.xml every month?
From now on we want to store all our sitemap.xml over the next years. Its a nice archive to have that allows us to analyse how many pages we have on our website and which ones were removed/redirected. Any suggestions? Thanks
Technical SEO | | DeptAgency0 -

How Does Google's "index" find the location of pages in the "page directory" to return?
This is my understanding of how Google's search works, and I am unsure about one thing in specific: Google continuously crawls websites and stores each page it finds (let's call it "page directory") Google's "page directory" is a cache so it isn't the "live" version of the page Google has separate storage called "the index" which contains all the keywords searched. These keywords in "the index" point to the pages in the "page directory" that contain the same keywords. When someone searches a keyword, that keyword is accessed in the "index" and returns all relevant pages in the "page directory" These returned pages are given ranks based on the algorithm The one part I'm unsure of is how Google's "index" knows the location of relevant pages in the "page directory". The keyword entries in the "index" point to the "page directory" somehow. I'm thinking each page has a url in the "page directory", and the entries in the "index" contain these urls. Since Google's "page directory" is a cache, would the urls be the same as the live website (and would the keywords in the "index" point to these urls)? For example if webpage is found at wwww.website.com/page1, would the "page directory" store this page under that url in Google's cache? The reason I want to discuss this is to know the effects of changing a pages url by understanding how the search process works better.
Technical SEO | | reidsteven750 -

Blocking URL's with specific parameters from Googlebot
Hi, I've discovered that Googlebot's are voting on products listed on our website and as a result are creating negative ratings by placing votes from 1 to 5 for every product. The voting function is handled using Javascript, as shown below, and the script prevents multiple votes so most products end up with a vote of 1, which translates to "poor". How do I go about using robots.txt to block a URL with specific parameters only? I'm worried that I might end up blocking the whole product listing, which would result in de-listing from Google and the loss of many highly ranked pages. DON'T want to block: http://www.mysite.com/product.php?productid=1234 WANT to block: http://www.mysite.com/product.php?mode=vote&productid=1234&vote=2 Javacript button code: onclick="javascript: document.voteform.submit();" Thanks in advance for any advice given. Regards,
Technical SEO | | aethereal
Asim0